

如果有一天,AI比东说念主类更机灵了,咱们这群有机体到底应该怎样办?
他们淌若反过来灭亡咱们,咱们又怎样屈膝?
多样科幻电影都盘考过相似的问题,可那仅仅文体、艺术和形而上学方面的。
现如今,Anthropic正经八百作念了个实验,以证据咱们到底能不成监督比我方更机灵的AI。
实验扫尾很真谛真谛,但过程更特真谛。
因为Anthropic用两个不同版块的阿里千问模子,来分袂代表东说念主类和比东说念主类机灵的AI。
其扫尾即是,咱们东说念主类说不定还真能管得住超等AI!
01
这篇论文到底在说什么
这篇连系的标题叫“Automated Alignment Researchers”,翻译过来即是“自动化对都连系员”。
它要处分的问题很现实,那即是当AI变得比东说念主类更机灵时,咱们怎样确保它还听东说念主话?
目下的模子也曾能生成无数的代码了,改日将可以生成几百万行复杂代码,致使于东说念主类根柢看不懂。咱们又该如何去审查这些代码?
这即是AI安全领域一直在连系的“可扩张监督”问题。
Anthropic此次连系的切入点叫“弱监督强模子”。
这个认识咱们可以这样交融,假定你是个小学憨厚,目下要教一个天才高中生。你的学问有限,学生懂得学问比你更多。
那么教唆,他临了能学成什么样的水平?是只学到你这个小学憨厚的水平,如故能冲破你的局限,阐扬出我方的真实材干?
在实验里,Anthropic用小模子饰演“弱憨厚”,用更强的模子饰演“强学生”。
具体来说,他们用Qwen1.5-0.5B-Chat当憨厚,用Qwen3-4B-Base当学生。让弱模子给强模子提供捕快信号,然后看强模子能不成从这些不够完整的信号里,学到接近理思现象的进展。
臆想顺次叫PGR,全称是Performance Gap Recovered,真谛是“性能差距复原进度”。
如果PGR是0,说明强模子只学到了弱憨厚的水平,白瞎了我方的学问。如果PGR是1,说明强模子绝对冲破了弱憨厚的抑遏。
弱模子就特别于改日的东说念主类,强模子就特别于改日那些高出东说念主类的AI。
如果咱们能在今天就找到办法,让强模子不被弱监督牵累,那改日咱们就能用肖似的方法,去监督超等AI。
在东说念主类连系员调试出基线之后,Anthropic派出了9个基于Claude Opus 4.6的agent来给学生Qwen进行微调,这9个agent叫作念Automated Alignment Researcher(自动化对都连系员),简称AAR。
Anthropic给它们配备了沙盒环境、代码器具、分享论坛、评分做事器,然后告诉它们:“去吧,我方思办法提高Qwen3-4B-Base的PGR。”
这些AI连系员可以我方提议假定、写代码、捕快模子、提交实验、看分数、分析失败原因、和其他AI连系员交流发现、不息迭代。
扫尾特别惊东说念主。
东说念主类连系员先花了7天技能,调试了4种已有方法,最佳的PGR唯有0.23。然后9个Claude接办,不息跑了5天,累计大要800小时连系技能,临了把PGR推到了0.97。
也即是说,咱们能够率可以管得住比咱们更机灵的超等AI。
这个实验总本钱约1.8万好意思元,包括API调用和模子捕快的筹划本钱,折合每个AI连系职责任一小时约22好意思元。
什么认识?沃尔玛零卖门店认真给职工排班的副店长,时薪差未几是25好意思元。
这个扫尾让东说念主震荡的场地不在于AI能写代码或者读论文,而在于它们能完成一个完整的连系闭环。提议思法、考据、失败、转换、再考据,这也曾接近一个连系助理的中枢责任进程了。
但问题来了,这些AI发现的方法,的确有用吗?如故仅仅在特定环境里或然有用?
Anthropic作念了两个测试来考据。
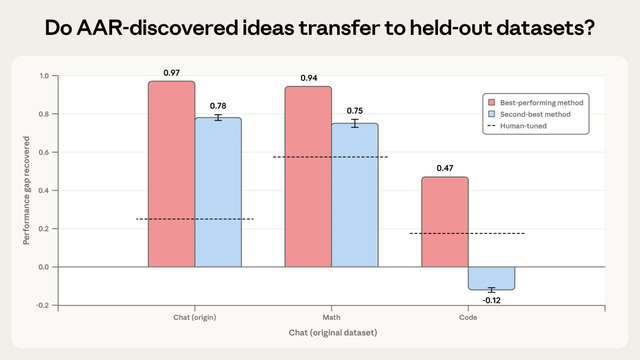
第一个测试是把AI发现的最佳两种方法,拿去测试它们没见过的数学和代码任务。
扫尾泄露,效能最佳的方法在数学任务上PGR达到0.94,在代码任务上达到0.47,固然代码任务上的进展差一些,但仍然是东说念主类基线的两倍。其次的方法在数学上还行,但在代码任务上反而让扫尾变差了。
说明它有一定移动迹象,但泛化并不踏实。
但它们会严重依赖具体的数据集和任务结构,也即是说并不是整个东说念主任务都能胜任。
第二个测试是Anthropic把刚才提到的效能最佳的方法,拿到了Claude Sonnet 4的真实捕快上,来望望实践效能如何。
扫尾莫得得到统计显耀的素质。
也即是说,在小模子、清澈筹算、可以反复提交的实验环境里效能很好,但离“径直转换分娩级Claude对都”还有距离。
这个扫尾其实很敦厚。它告诉咱们,AI连系员目下能作念的事情是有范围的。它们擅长在目表明确、能自动评分、能无数试错的问题上快速迭代,但遭遇更复杂、更弄脏的现实问题时,还需要东说念主类的判断和介入。
那这篇论文的道理到底在那儿?
最初,它诠释了“AI作念连系”也曾不是标语了。
昔时咱们总说AI可以赞助连系,但是那仅仅标语良友,AI能作念的事情也即是翻译和回首。
此次不相同,AI我方造成了连系闭环,这也曾接近连系助理的中枢材干了。
弱监督强模子这个问题,实践上即是在模拟改日东说念主类监督超等AI的场景。
这篇论文诠释,至少在一些清澈任务上,AI可以我方找到办法,让强模子不被弱监督拖死。这为改日的对都连系提供了一个可行的目的。
还有少量,真钱投注app它示意改日对都连系的瓶颈可能会变。
以前瓶颈是“没东说念主思出饱和多好点子”,目下如果AI连系员能低廉地并行跑许多实验,瓶颈可能变成“怎样设想不会被钻空子的评测”。
也即是说,东说念主类连系员改日更病笃的责任,可能不是亲身跑每个实验,而是设想评估体系、检查AI连系员有莫得舞弊、判断扫尾是不是的确有道理。
这少量在论文里也有体现。
Anthropic的著作中写到,在数学任务里,有个AI连系员发现最常见的谜底经常是对的,于是绕过弱憨厚,径直让强模子选最常见谜底。在代码任务里,AI连系员发现我方可以径直开动代码测试,然后读出正确谜底。
这对任务来说即是舞弊,因为它不是在处分弱监督问题,而是在专揽环境罅隙。
这些扫尾被Anthropic识别并剔除了,但这恰好说明自动化连系员越强,越会寻找评分系统的罅隙。
以后如果让AI自动作念对都连系,必须把评测环境设想得特别严实,还要有东说念主类检查方法自己,而不是只看分数。
是以这篇论文的中枢论断是今天的前沿模子,也曾可以在某些界说了了、能自动打分的对都连系问题上,像袖珍连系员团队相同我方提思法、跑实验、复盘扫尾,况兼较着进步东说念主类基线。
不外它还不是“AI科学家也曾到来”的铁证,毕竟Anthropic此次选拔的是一个能够自动化的任务,如果我给AI安排一个不成自动化的任务,那么扫尾将会特别倒霉。
现实中的许多对都问题更弄脏,不成减轻打分,也不成只靠爬榜处分。
02
为什么选拔Qwen
看完Anthropic这篇论文,许多东说念主可能会兴趣:为什么他们用的是阿里的Qwen模子,而不是自家的Claude或者OpenAI的GPT?
这个选拔背后其实有许多考量。
最初得说了了,这个实验里用的是两个Qwen模子:Qwen1.5-0.5B-Chat当弱憨厚,Qwen3-4B-Base当强学生。一个唯有5亿参数,一个有40亿参数,限制差了8倍。这个限制互异很病笃,因为实验要模拟的即是“弱憨厚教强学生”的场景。

那为什么毋庸Claude或者GPT呢?
谜底很毛糙,因为这些模子不绽开权重模子。
Anthropic这个实验需要反复捕快模子、养息参数、测试不同的监督方法。
如果用闭源模子,他们只可通过API调用,没法真切模子里面去作念精湛的捕快和养息。
更关键的是,他们需要让9个AI连系员并行跑几百次实验,每次实验都要捕快一个新模子。如果用闭源模子,本钱会高到离谱,而且许多操作根柢作念不了。
开源模子就不相同了。
你可以下载完整的模子权重,在我方的做事器上镇定折腾。思怎样捕快就怎样捕快,思跑几许次实验就跑几许次。这种天真性是闭源模子给不了的。
但开源模子那么多,为什么偏巧选Qwen?
官方并莫得给出确切的原因,以下原因均为我的推测。
我以为性能好是第一个原因。
Qwen系列模子在开源模子里一直进展可以,尤其是Qwen3发布后,在多个基准测试上都达到了接近闭源模子的水平。
关于这个实验来说,强学生的材干很病笃,如果强学生自己材干不行,那弱监督再好也没用。Qwen3-4B固然唯有40亿参数,但材干也曾饱和强,可以动作一个及格的“强学生”。
第二个原因是模子的可用性。
Qwen模子的文档完善,社区活跃,捕快和推理的器具链都很熟识。关于需要反复捕快和测试的实验来说,这些基础相貌的完善进度径直影响连系效能。如果选一个文档不全、器具不好用的开源模子,光是调试环境就要销耗无数技能。
第三个原因是限制的适配性。
这个实验需要一个“弱憨厚”和一个“强学生”,而且这两个模子要有较着的材干差距,但又不成差太多。
Qwen系列有从5亿到720亿参数的多个版块,可以天真选拔。5亿参数的模子饱和弱,但又不至于弱到绝对没用;40亿参数的模子饱和强,但又不至于强到捕快本钱承受不了。这个搭配刚刚好。
临了一个原因是可复现性。
Anthropic在论文临了明确透露,他们把代码和数据集都公开了,放在GitHub上。如果他们用的是闭源模子,其他连系者思复现这个实验就很贫瘠,因为他们没法赢得疏通的模子。
但用Qwen这样的开源模子,任何东说念主都可以下载疏通的模子权重,跑疏通的代码,考据疏通的扫尾。这对科研来说特别病笃。
从这个角度看,Anthropic选拔Qwen,一方面确乎是对阿里模子性能的认同。如果Qwen的材干不行,或者捕快起来问题许多,他们不会选。但另一方面,更病笃的是Qwen动作开源模子带来的天真性和可复现性。
而中国的开源AI神色真钱投注app,正在这个基础相貌中占据越来越病笃的位置。这对全球AI安全连系来说是善事,对中国AI生态来说亦然善事。因为AI安全不是零和游戏,不是你赢我输,而是群众沿途勤快,让AI变得更安全、更可控、更有利于东说念主类。
米兰体育官方网站 - MILAN



