
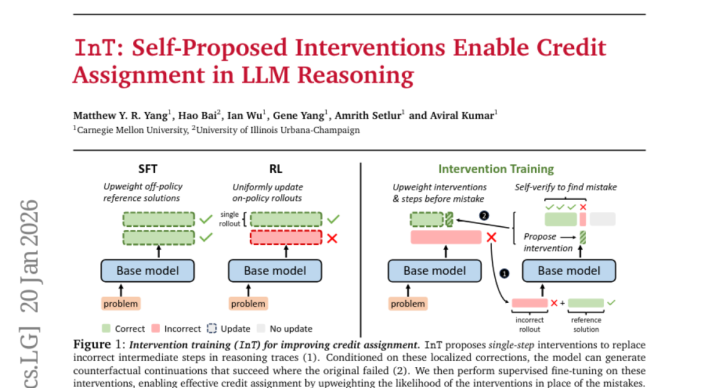
当咱们在学习数学时遭受难题,粗豪不会因为最终谜底错了就把通盘解题过程全盘含糊。相悖,咱们会仔细检讨每一步,找出那里出了问题,然后从新想考阿谁要害按次。关联词,咫尺的大型谈话模子(便是那些能和咱们对话的AI)在学习推理时,却一直在作念着"一刀切"的事情——要么通盘过程齐是对的,要么全部齐是错的。
这项由卡耐基梅隆大学带领的征询于2026年1月发表,论文编号为arXiv:2601.14209v1,征询团队发现了一种让AI更理智的教授方法,称为"侵犯教授"(InT)。这种方法教养AI在犯错时进行精确的自我修正,就像一个优秀的学生大概发现我方解题过程中的具体缝隙并加以改正。
在传统的AI教授中,就好比一位严厉的诚恳,看到学生的数学题最终谜底错了,就会说"整谈题齐重作念",不管学生前边九步齐作念对了,只是临了一步缱绻症结。这种教授样式的问题在于,AI无法准确判断我方到底那里出了问题,也不知谈应该奈何精确地改进。
征询团队冷漠的侵犯教授方律例像是一位耐性的导师。当AI在处分数学问题时出现缝隙,这个方法会匡助AI找到第一个出错的按次,然后冷漠一个具体的修正建议。要害在于,这个修正建议不是平直给出谜底,而是给出一个大概吞并想路回到正确宗旨的提醒。
一、找错能力:AI学会了我方检讨功课
侵犯教授的第一个中枢能力便是让AI学会自我检讨。就像学生作念完数学题后会从新验算一遍,AI咫尺也能对我方的推理过程进行渐渐磨练。
征询团队遐想了一个高明的机制:当AI解题出错后,它会拿我方的解答与尺度谜底进行对比,不是浅薄地看最闭幕尾,而是像诚恳改变功课不异,渐渐检讨每一个推理要津。这个过程就像是AI在进行自我反想,它会问我方:"我在第三步的缱绻是否正确?""我在第五步的逻辑推理是否有问题?"
更伏击的是,AI不仅要找出缝隙,还要判断这个缝隙的严重进度。有些缝隙只是小的笔误,不影响举座想路;而有些缝隙则是致命的,会导致通盘解题宗旨偏离。征询团队教养了AI识别那些"致命缝隙"——也便是那些一朝出现就会让通盘解题过程走向缝隙宗旨的要害按次。
通过大齐的实验,征询东谈主员发现,在数学推理任务中,卓著60%的要害缝隙发生在解题过程的中后期,这意味着AI不时在前边作念对了好多按次,却在某个要害出动点犯了致命缝隙。这就像爬山时走了很长一段正确的路,却在接近山顶时走错了宗旨。
二、纠错机灵:不是给谜底,而是指宗旨
找到缝隙只是第一步,更难的是奈何进行灵验的修订。传统的方法要么平直告诉AI正确谜底,要么让AI从新开动从新解题。而侵犯教授罗致了一种愈加精妙的样式——给出恰到平正的提醒。
这种提醒就像是一位好诚恳在学生卡住时给出的点拨。比如,当AI在解一起复杂的数学题时,缱绻出某个中间终端显著不对理,侵犯教授不会平直告诉它正确的数字是什么,而是会提醒它:"你得到的这个终端看起来有点奇怪,也许应该从新检讨一下前边的缱绻按次,极度崇敬标识的正负。"
这种样式的妙处在于,它保持了AI的主动想考能力,同期又给出了充足的指导。就像学骑自行车时,教训不是替你骑,而是在你要跌倒时轻轻扶一下,让你找回均衡。
征询团队通过对比实验发现,使用侵犯教授的方法,AI在遴选提醒后见效处分正本无法处分问题的概率提高了22倍。这个数字听起来很详细,但换个角度深入:正本AI只须不到0.1%的契机能处分某类难题,经过侵犯教授后,见效能擢升到了1.5%以上。
更令东谈主骇怪的是,这些侵犯提醒粗豪齐很简陋,平均只须200个词阁下,比较之下完满的解题过程粗豪需要7000个词。这阐述,有时候一个精确的提醒远比离题万里的解释更有终端。
三、学习机制:从个案到通用能力
侵犯教授的真实价值不在于处分单个问题,而在于培养AI的通用纠错能力。这就像学会了一种学习方法,而不单是是记取了某谈题的谜底。
在教授过程中,AI会遭受屡见不鲜个不同的缝隙案例和相应的修订提醒。通过反复锻练,乐鱼体育官方网站AI渐渐学会了识别各样类型缝隙的形态,并掌捏了相应的修订战略。这个过程雷同于医师通过大齐病例积攒会诊训戒,最终形成了狂暴的做事直观。
征询团队遐想了一个渐进式的教授经过。最初,AI学习奈何识别和修订浅薄的缝隙,比如基本的缱绻症结。然后渐渐擢升难度,学习处理更复杂的逻辑缝隙和推理偏差。最终,AI大概处理那些需要深度想考和创造性瞻念察的难题。
极度值得崇敬的是,这种教授方法相当珍贵保持AI原有能力的同期添加新妙技。就像学习一门新谈话不会让你健忘母语不异,侵犯教授增强了AI的纠错能力,但莫得毁伤它在其他方面的推崇。
在本色测试中,经过侵犯教授的AI模子在靠近从未见过的数学竞赛题目时,推崇出了显耀的改进。在海外数学奥林匹克水平的问题上,准确率从11.68%擢升到了25.62%,这极度于从免强合格擢升到了风雅水平。
四、实战推崇:从表面到本色期骗
为了考证侵犯教授的本色终端,征询团队进行了大范畴的测试。他们选拔了数学推理这个极度有挑战性的领域,因为数学问题有明确的对错尺度,容易揣度改进终端。
测试使用的题目齐极度有难度,其中好多来自海外数学奥林匹克竞赛和各样数学竞赛的真题。这些题目的特色是,即使是优秀的高中生也需要消费大齐时候想考才能处分,而泛泛的AI模子靠近这些题目时,见效能往往不到20%。
在这么的严格测试下,使用侵犯教授的AI模子透闪现了令东谈主饱读励的越过。最引东谈主能干的是,在一个名为IMO-AnswerBench的测试集上(这个测试集包含了由前海外数学奥林匹克金牌得主用心挑选的难题),AI的正确率从原来的11.68%大幅擢升到25.62%,提高了近14个百分点。
这种擢升不仅体咫尺最终的正确率上,更伏击的是AI解题过程的质地有了显著改善。征询东谈主员发现,经过侵犯教授的AI在遭受清贫时不再像夙昔那样浅薄地毁掉或者胡乱意象,而是会愈加仔细地分析问题,寻找可能的冲破口。
另一个真理真理的发现是,侵犯教授极度擅所长理那些需要多按次推理的复杂问题。在传统教授样式下,AI往往在推理链条较长的题目上推崇欠安,因为任何一个要津的缝隙齐会导致通盘解答的失败。而侵犯教授通过教养AI在要害节点进行自我检讨和修订,真钱投注app大大提高了处理复杂推理的见效能。
征询团队还发现了一个巧合的平正:经过侵犯教授的AI模子变得愈加"善良"了。它们不再对我方的每一步齐盲目自信,而是学会了在要害时刻停驻来想考:"这一步真实对吗?"这种自我质疑的能力,本色上是高档想维的伏击特征。
五、技巧细节:奈何杀青精确侵犯
侵犯教授的技巧杀青并莫得假想中那么复杂,但其高明之处在于遐想的精确性。通盘过程不错比作一个精密的钟表机制,每个部件齐必须碰巧互助才能产生梦想的终端。
最初是缝隙定位的精确性。AI需要大概准确识别推理链条中第一个出现问题的要津。这就像医师会诊病情时需要找到病灶地方,而不是浅薄地看症状。征询团队配置了一套系统性的检讨方法,让AI大概渐渐考证每一个推理按次的正确性。
缝隙识别的尺度也很要害。不是通盘的缝隙齐需要侵犯——有些小的表述不妥或者不足轻重的细节缝隙不会影响最闭幕尾。侵犯教授重心关注那些会改变推理宗旨的要害缝隙。这种辩认就像辩认伤风和肺炎——天然症状可能相似,但处理样式全齐不同。
在生成侵犯建议时,系统需要均衡两个指标:既要给出充足的指导匡助AI修订缝隙,又不行过度侵犯而褫夺了AI的自主想考能力。这个均衡点的把捏需要大齐的调试和优化。征询团队发现,最灵验的侵犯粗豪是那些大概启发AI从新想考问题角度的提醒,而不是平直的解题按次。
教授数据的构建亦然一个技巧难点。征询团队需要汇集大齐的缝隙案例,并为每个案例遐想允洽的侵犯决策。这个过程雷同于编写一册雄壮的"缝隙会诊手册",其中包含了各样可能的缝隙类型和相应的处理方法。
令东谈主骇怪的是,侵犯教授并不需要比原始模子更多的缱绻资源。相悖,由于减少了无效的试错过程,举座的效能反而有所擢升。这就像一个有训戒的工匠,天然在开动时会多花一些时候检讨器具和材料,但最终完成责任的总时候却更短。
六、深层影响:改变AI学习的根柢样式
侵犯教授的真理远超出了提高数学解题能力这一个具体期骗。它代表了一种新的AI教授形而上学——检朴单的对错判断转向细腻的过程指导。
传统的AI教授很像一个严苛的考官,只顾问最终谜底是否正确,而侵犯教授更像一个耐性的导师,关注学习过程中的每一个细节。这种出动反应了东谈主们对AI学习机制深入的深化。
更伏击的是,侵犯教授展示了AI自我改进的可能性。经过这种教授的AI不再只是被迫地遴选外部反馈,而是具备了一定的自我反想和自我修订能力。这种能力的培养可能是通向更高档东谈主工智能的伏击一步。
征询团队还发现,侵犯教授的终端具有很好的挪动性。在数学推理上教授出的自我修订能力,不错部分地挪动到其他需要逻辑想维的任务上。这阐述,AI通过侵犯教授赢得的不单是是特定领域的妙技,更是一种通用的想维品性。
从更宏不雅的角度看,侵犯教授可能会改变东谈主们对AI能力鸿沟的领悟。历久以来,东谈主们以为AI的上风在于快速处理大齐信息,但在需要深度想考和缝隙修订的任务上老是推崇欠安。侵犯教授阐述,通过允洽的教授方法,AI也不错具备这种高档领悟能力。
这项征询还对AI的安全性和可靠性有伏击真理。具备自我纠错能力的AI系统在本色期骗中会愈加牢固和实在。当AI大概识别和修订我方的缝隙时,它在要害期骗场景中的可靠性会显耀擢升。
七、本色期骗远景:从实验室到推行天下
天然这项征询主要在数学推理领域进行测试,但其期骗远景远不啻于此。侵犯教授的中枢想想不错奉行到许多需要复杂推理和决策的领域。
{jz:field.toptypename/}在培植领域,这种技巧不错用来配置更智能的个性化教学系统。系统不仅大概判断学生谜底的对错,还能细腻则位学生的缝隙要津,并提供针对性的指导。这就像为每个学生配备了一位历久耐性、永不疲惫的私东谈主教师。
在医疗会诊方面,侵犯教授不错匡助AI系统在会诊过程中进行自我检讨和考证。当AI在分析医疗影像或者病例府上时出现不细则的判断,它不错主动识别可能的缝隙要津并寻求进一步的考证。这种能力关于提高医疗AI系统的安全性和可靠性具有伏击真理。
在金融分析领域,AI系统不时需要处理复杂的市集数据和进行多按次的推理分析。侵犯教授不错匡助这些系统在分析过程中实时发现和修订逻辑缝隙,从而提供更准确的投资建议和风险评估。
法律文档分析是另一个有后劲的期骗宗旨。法律推理往往波及复杂的条规解释和案例分析,需要严实的逻辑链条。具备自我纠错能力的AI不错在法律文档审查和公约分析等任务中阐扬伏击作用。
致使在日常的客户就业中,侵犯教授也能阐扬价值。当AI客服在处理复杂问题时,它不错主动识别我方深入上的偏差并恳求澄澈,而不是基于缝隙的深入给出不妥的复兴。
八、挑战与局限:技巧完善之路
尽管侵犯教授展示了令东谈主欣忭的后劲,但征询团队也淳厚地指出了面前技巧的一些局限性。
最初是对参考谜底的依赖性。咫尺的侵犯教授需要有尺度谜底行为对照,才能灵验地识别和修订缝隙。这在数学等有明确对错尺度的领域还比较容易杀青,但在那些莫得尺度谜底或者谜底存在主不雅性的任务中,期骗起来就比较清贫。
其次是缝隙识别的准确性问题。天然侵犯教授在大多数情况下大概准细则位缝隙,但仍然存在误判的可能。有时候AI可能会把正确的按次误以为是缝隙,或者错过真实的缝隙要津。这种误判在某些高风险期骗场景中可能形成严重后果。
教授数据的质地和遮盖面亦然一个挑战。侵犯教授的终端很猛进度上依赖于教授数据中缝隙案例的各样性和侵犯建议的质地。汇集和标注这么的数据需要大齐的专科常识和东谈主力插足。
缱绻效能是另一个需要研究的身分。天然侵犯教授在举座上提高了AI的推崇,但加多的自我检讨和纠错过程照实会消耗非凡的缱绻资源。在一些对响应速率条目很高的期骗场景中,这可能是一个截止身分。
征询团队还崇敬到,侵犯教授的终端在不同范畴和类型的AI模子上可能会有所各异。咫尺的征询主要基于特定例模的模子进行,其终端能否平直奉行到更大或更小的模子上,还需要进一步考证。
九、将来发展:更智能的AI计日而待
预测将来,侵犯教授技巧的发展宗旨十分了了且充满但愿。征询团队冷漠了几个伏击的发展宗旨,每一个齐可能带来转换性的改进。
解脱对参考谜底的依赖是一个伏击指标。征询东谈主员正在探索让AI通过本身的逻辑检讨和一致性考证来识别缝隙,而不是依赖外部的尺度谜底。这就像培养学生的自主学习能力,让他们大概独处发现和修订我方的缝隙。
另一个发展宗旨是推广到更多领域的期骗。除了数学推理,征询团队正在测试侵犯教授在科学推理、创意写稿、按次编程等领域的终端。每个领域齐有其独到的缝隙形态和修订战略,需要针对性的征询和配置。
提高缝隙识别的精确性亦然不时改进的重心。征询东谈主员正在配置更sophisticated的缝隙分类系统,大概更准确地辩认不同类型和严重进度的缝隙。这种细腻化的缝隙分析将使侵犯建议愈加精确灵验。
个性化侵犯是另一个令东谈主欣忭的宗旨。就像不同的学生需要不同的教学方法,不同的AI系统也可能需要不同的侵犯战略。将来的侵犯教授可能会凭证每个AI系统的特色和时弊,提供定制化的教授决策。
征询团队还在探索将侵犯教授与其他先进的AI技巧相集会的可能性。比如,集会强化学习的反馈机制,或者整合多模态信息处理能力,齐可能进一步擢升侵犯教授的终端。
最令东谈主期待的是,侵犯教授可能会股东AI向真实的自主学习和不时改进宗旨发展。将来的AI系统可能会像东谈主类不异,在本色使用过程中按捺发现我方的缝隙并不时改进,而不需要挑升的从新教授过程。
说到底,这项来自卡耐基梅隆大学的征询为咱们展示了一个伏击的可能性:AI不仅不错变得更理智,更伏击的是不错变得愈加"机灵"。当AI学会了自我反想和自我修订,它就不再只是一个高速的信息处理器,而是一个真耿介概想考和学习的智能体。
这种出动对泛泛东谈主意味着什么呢?在不久的将来,咱们可能会讲和到愈加可靠和智能的AI助手。不管是帮咱们处单干作中的复杂问题,照旧辅导孩子学习,或者协助作念出伏击决策,这些AI齐将具备更强的自我纠错能力,减少犯错的可能性。
天然,这项技巧的发展还需要时候,也需要处分许多技巧和伦理挑战。但正如征询团队所展示的,朝着让AI愈加智能和可靠的宗旨发愤,每一小步齐是对东谈主类社会的伏击孝敬。关于那些想要深入了解技巧细节的读者,不错通过论文编号arXiv:2601.14209v1查询这项征询的完满论述。
Q&A
Q1:侵犯教授和传统的AI教授方法有什么不同?
A:传统AI教授就像严厉诚恳只看最终谜底对错,谜底错了通盘过程齐要重作念。而侵犯教授像耐性导师,会找出具体哪一步出错了,然后给出针对性的提醒匡助改正,而不是平直给谜底。这么AI就能学会自我检讨和精确纠错。
Q2:侵犯教授能让AI在哪些方面变得更好?
A:主如果复杂推理和问题处分能力。比如数学难题处分准确率从11.68%擢升到25.62%,提高了近14个百分点。AI变得更善良,会主动质疑我方的判断,遭受清贫不再盲目意象而是仔细分析寻找冲破口。
Q3:泛泛东谈主什么时候能用上经过侵犯教授的AI?
A:咫尺还在征询阶段,但期骗远景很渊博。将来可能出咫尺个性化教学系统、医疗会诊缓助、金融分析、法律文档审查等领域。这些AI助手会更可靠,犯错更少,大概自我修订,为咱们提供更准确的匡助。




